我开发了一个号称聪明的 AI 人性化处理工具,但我不确定它对真实读者来说是否自然,还是只是糊弄一些基础检测器。我需要坦诚的人类风格反馈和实用建议,帮我改进输出效果、提高可读性,并避免听起来像机器人。任何详细的评测、示例或优化建议都会对我有很大帮助。
Clever AI Humanizer:我实际使用后到底发生了什么
<img alt=’ src=‘https://mepis.org/community/uploads/default/original/image-1766509019.png’ height=‘524’ width=‘781’>
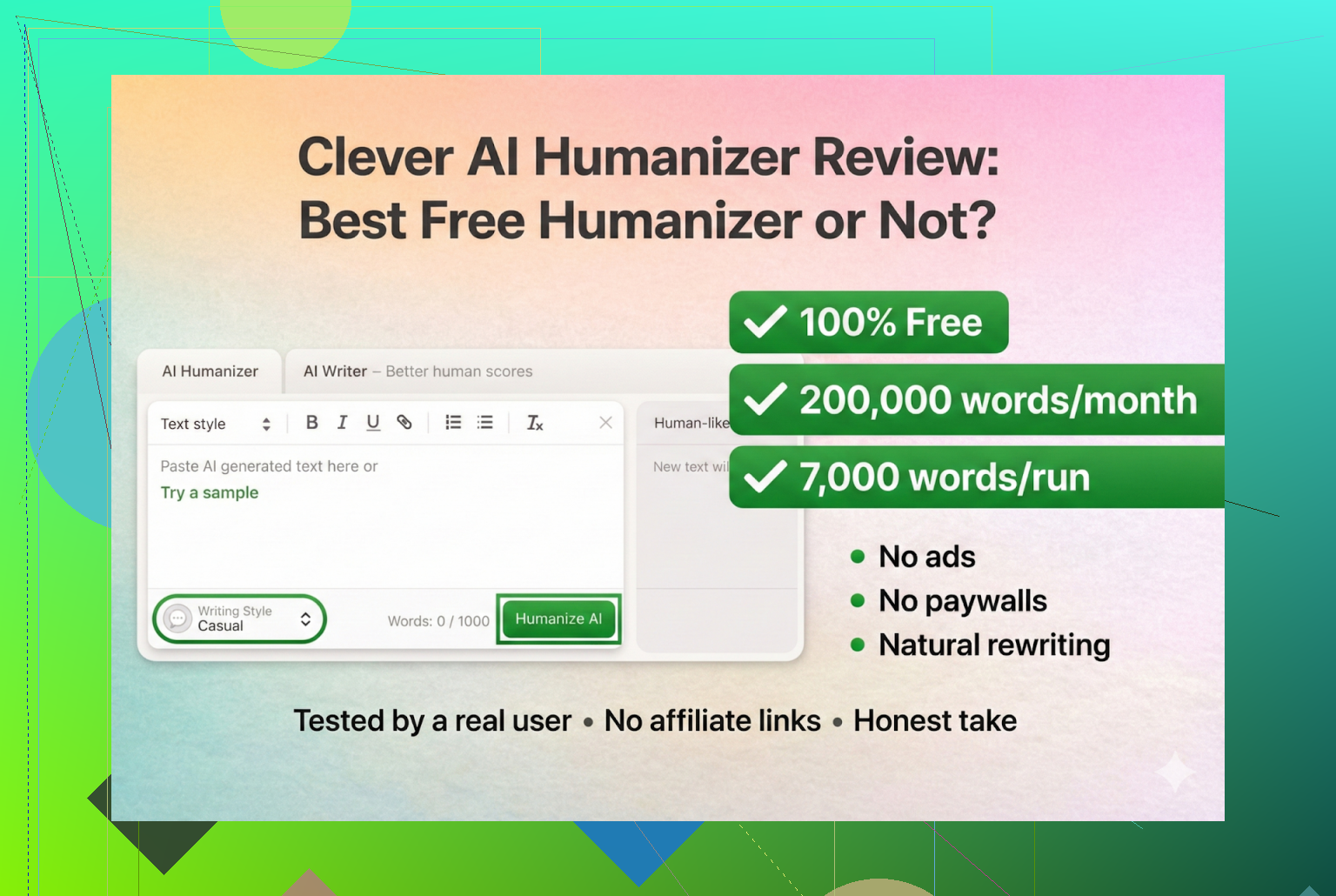{kind=link}
我最近在把市面上能找到的免费“AI 人类化工具”都过了一遍,其中一个名字反复出现:Clever AI Humanizer。
于是我做了大多数人不好意思承认的事:先让一个 AI 写关于 AI 人类化工具的文章,再用另一个 AI 来打分,最后把结果丢进多个 AI 检测器里测试。
相当“正常”的业余爱好。
我测试的工具在这里:
Clever AI Humanizer:https://aihumanizer.net/zh
这是正牌网站。记住这个 URL。外面有一堆克隆站。
先说重点:关于假“Clever AI Humanizer”网站
有几个人私信问我要“真正的” Clever AI Humanizer 链接,因为他们在广告里点进同名的“AI humanizer”网站被坑了。
有几点要注意:
- https://aihumanizer.net/zh 的 Clever AI Humanizer
没有付费版、没有订阅、没有什么升级销售。 - 如果你在一个号称是“Clever AI Humanizer”的网站上被要求绑定银行卡或开会员,那你大概率已经进了用同名品牌蹭流量的假站。
所以,在你开始往一个陌生文本框里疯狂贴作文之前,先看一眼 URL。
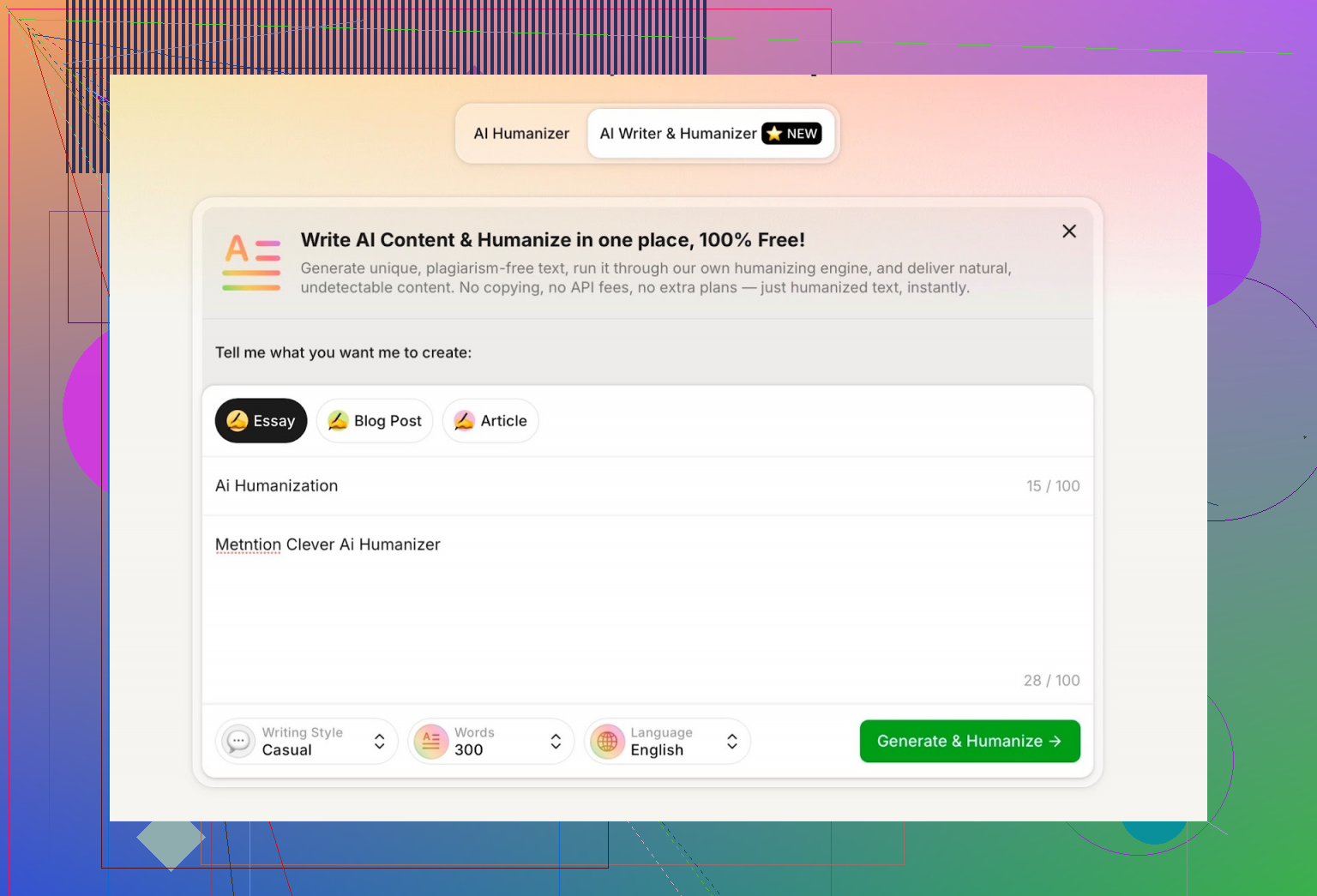
我到底怎么测的(测试流程)
我的玩法是尽量“整崩”它:
- 用 ChatGPT 5.2 生成一篇完全由 AI 撰写、介绍 Clever AI Humanizer 的长文。
- 把这篇文章丢进 Clever AI Humanizer。
- 选择 Simple Academic(简单学术) 模式进行改写。
- 把输出结果丢进几个主流 AI 检测器。
- 再让 ChatGPT 5.2 充当写作导师,对改写后的文章做点评。
为什么选 Simple Academic?因为它处在一个很微妙的区间:不是学术论文,但又比“随便写写的博客文”要正式。很多 humanizer 在这个层级都会翻车,因为结构一正规,检测器就更容易起疑心。
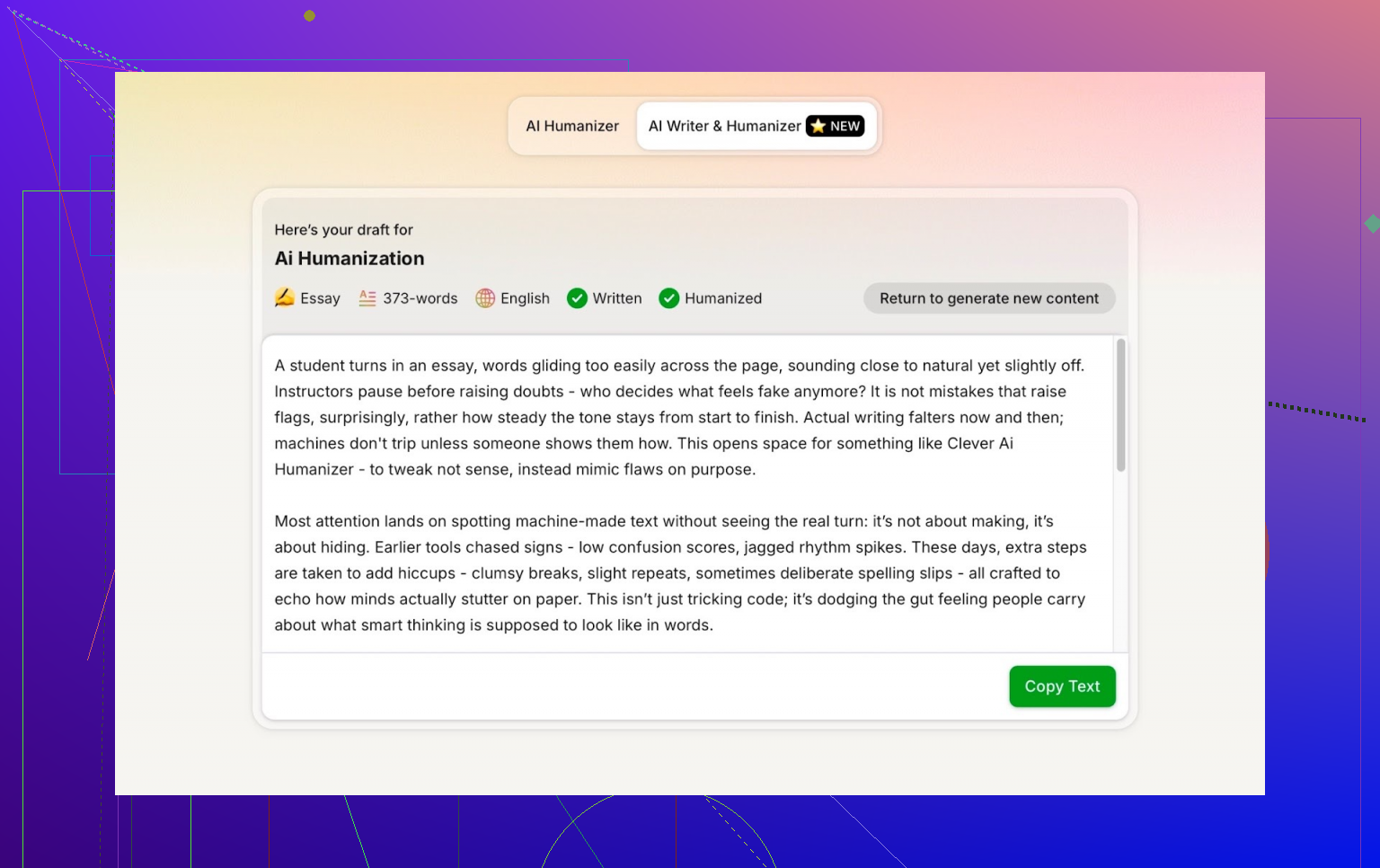
第一轮测试:使用 Clever AI Humanizer 的 “Simple Academic” 模式
<img alt=’ src=‘https://mepis.org/community/uploads/default/original/image-1766509022.png’ height=‘478’ width=‘823’>
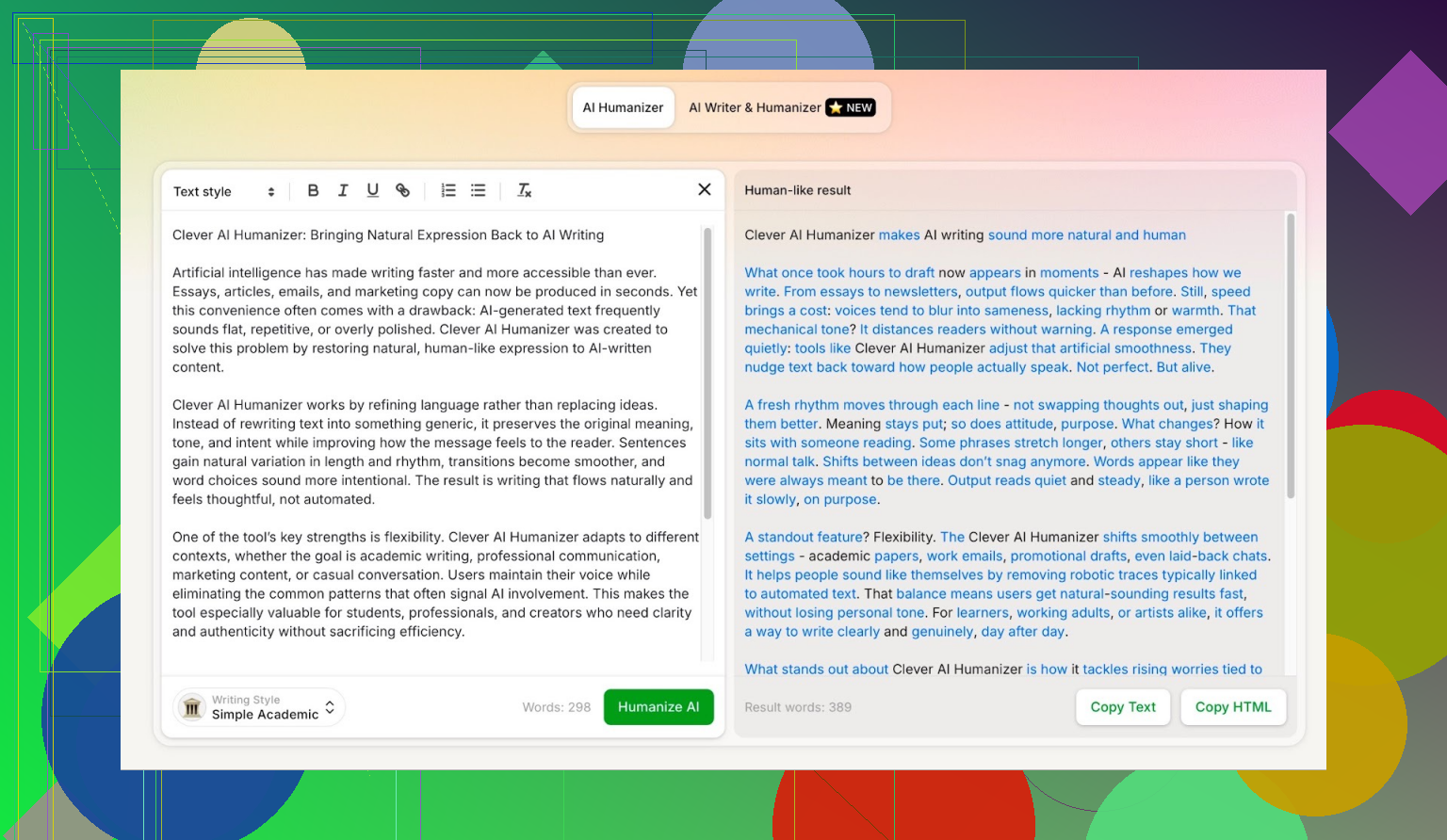{kind=link}
我把 ChatGPT 生成的全文贴进 Clever AI Humanizer,模式设为 Simple Academic,然后让它跑完。
接着就开始和各类检测器打地鼠。
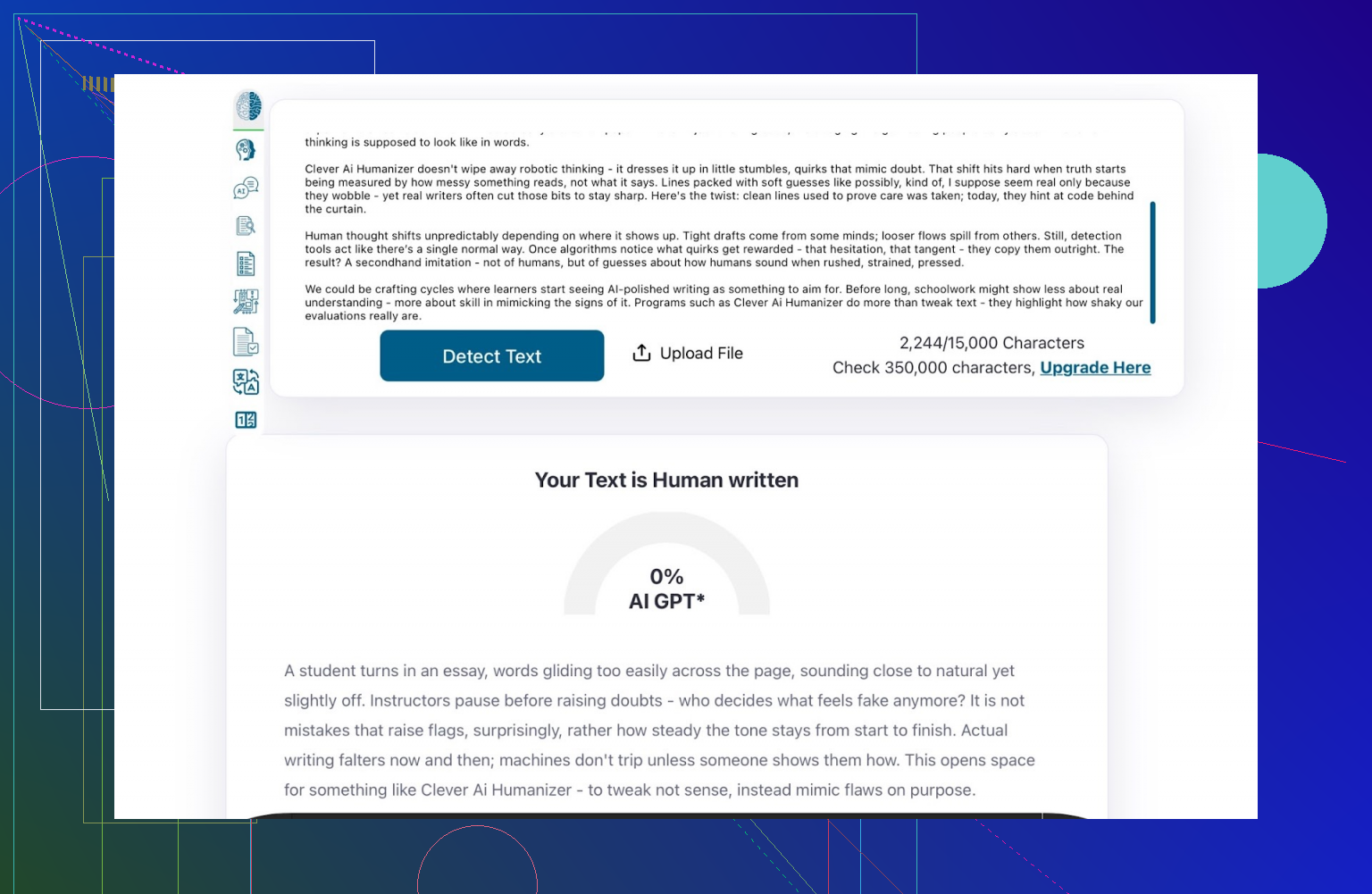
ZeroGPT
<img alt=’ src=‘https://mepis.org/community/uploads/default/original/image-1766509023.png’ height=‘495’ width=‘763’>
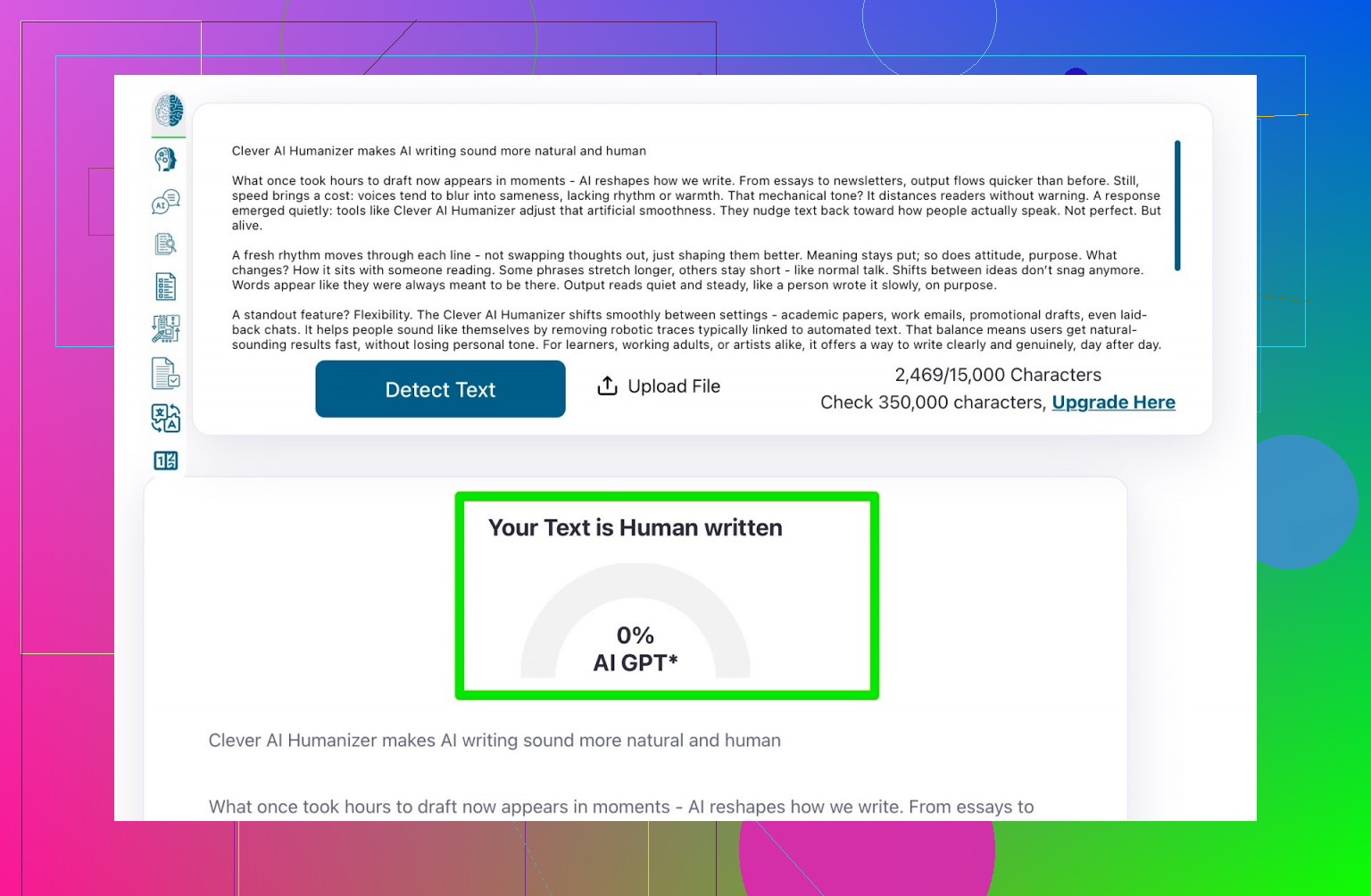{kind=link}
先上 ZeroGPT。
我并不打算长期把它当“真理”,因为它曾经把美国宪法判成“100% AI”,想象一下开国元勋在给 GPT 下指令的画面就有点离谱。
但这毕竟是很多人在 Google 上搜到、顺手就用的工具。
对 Clever Humanizer 输出文本的检测结果:
检测为 0% AI。
没有红条,没有“疑似 AI”,工具的结论就是“人类写的”。
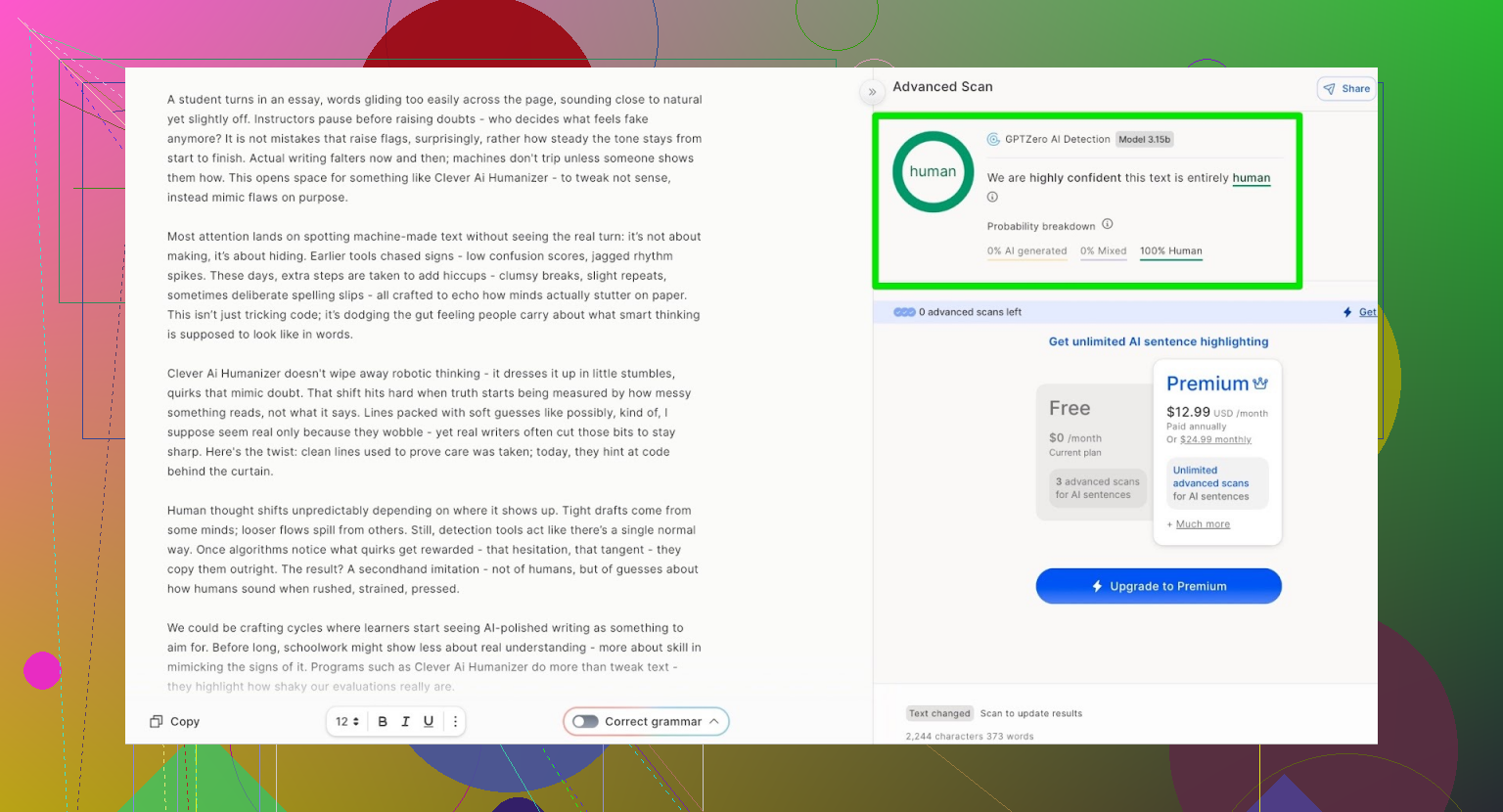
GPTZero
<img alt=’ src=‘https://mepis.org/community/uploads/default/original/image-1766509025.png’ height=‘448’ width=‘771’>
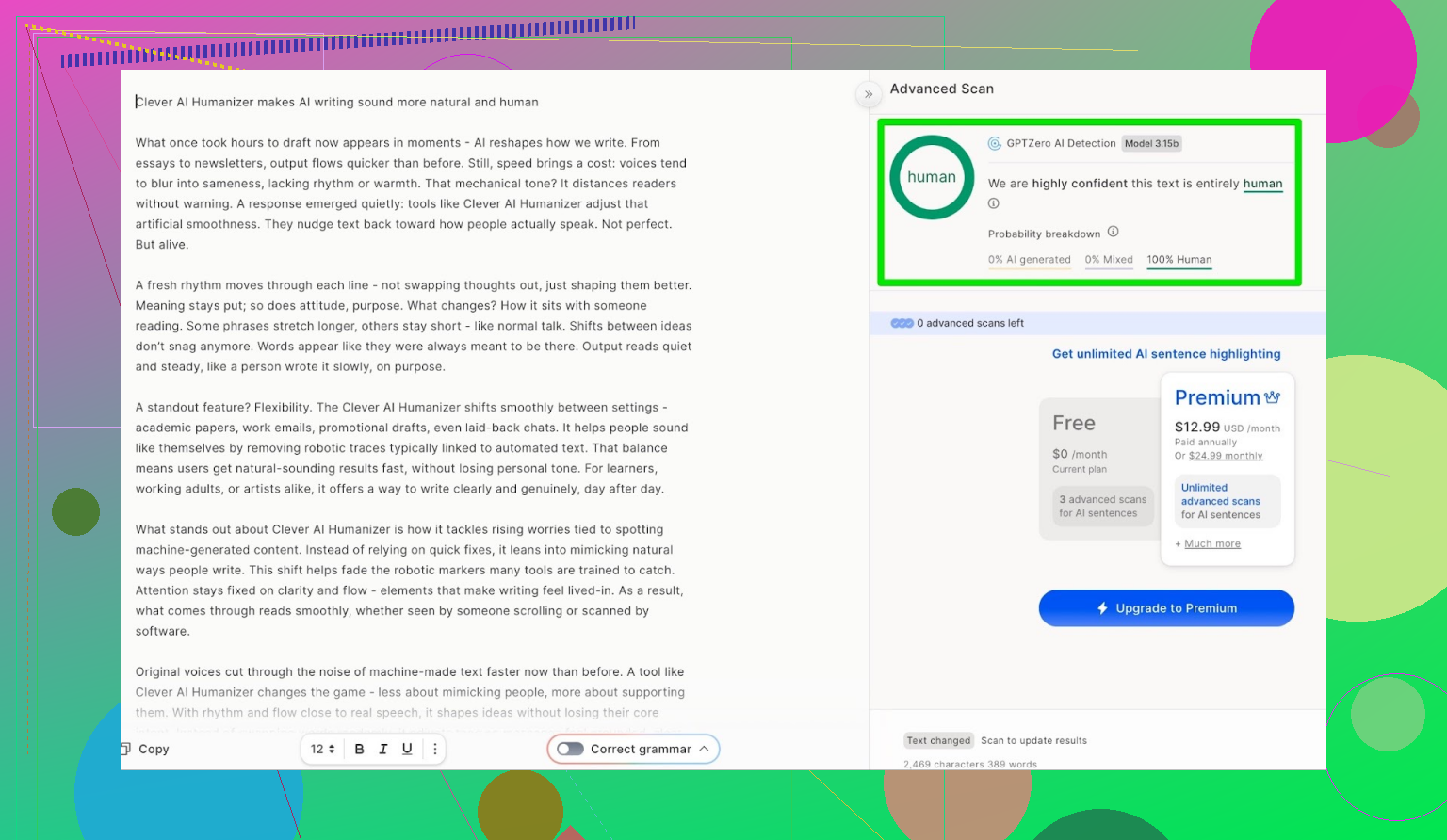{kind=link}
下一个是 GPTZero,大概是另一款很多人习惯拿来检测作文的工具。
同一段文字。
结果:
- 100% human
- 0% AI
也就是说,这两个最常见的公开检测器,都很淡定地表示:“看起来是人写的。”
但这篇文章本身到底好不好?
很多炫检测截图的分享,都会跳过这一点:
这东西你真的能拿去交作业、发出去、或者给客户看而不尴尬吗?
于是我让 ChatGPT 5.2 把 Clever AI Humanizer 的输出,当作学生论文来打分。
<img alt=’ src=‘https://mepis.org/community/uploads/default/original/image-1766509027.png’ height=‘613’ width=‘734’>
{kind=link}
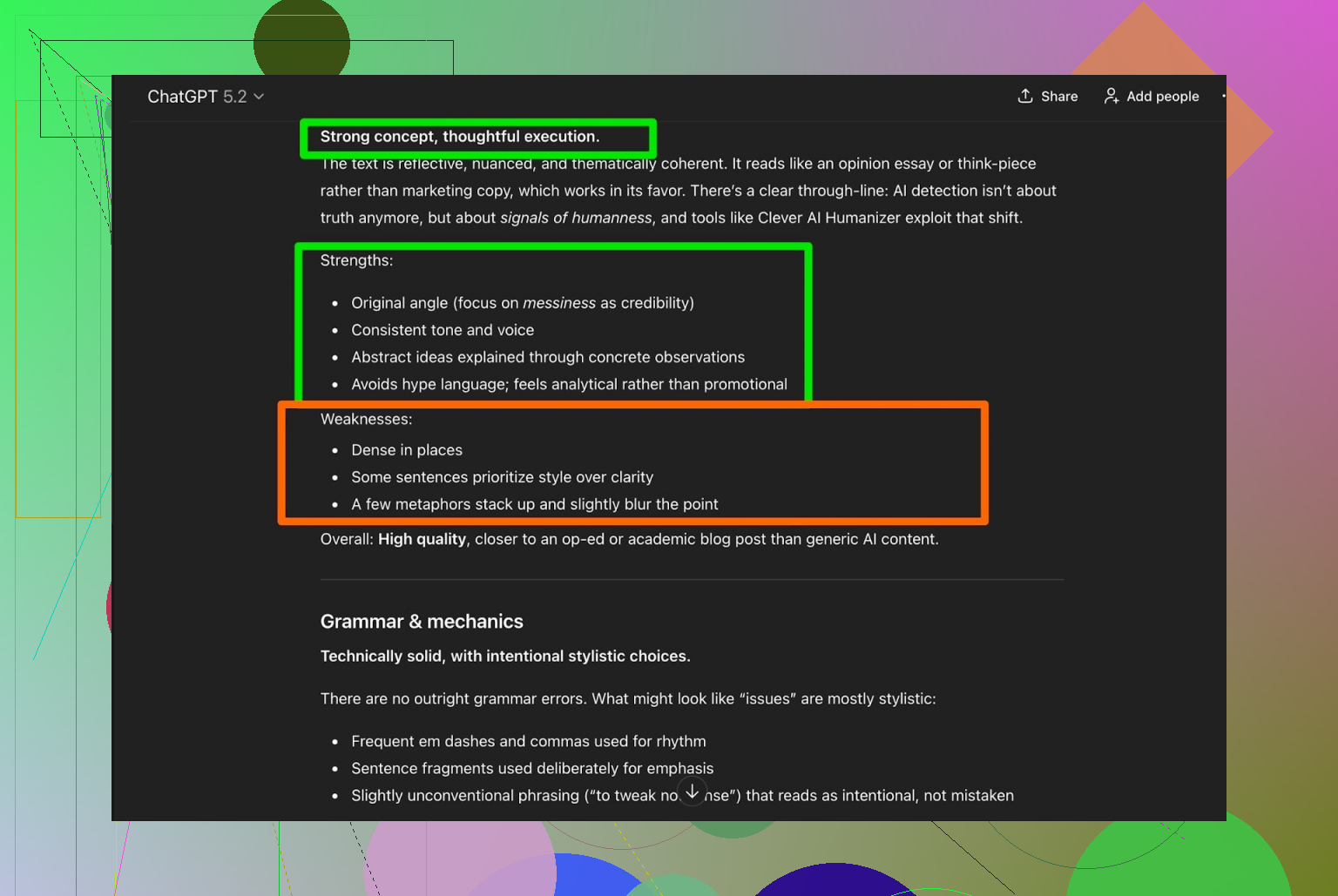
ChatGPT 的评价:
- 语法: 很扎实,没有明显硬伤。
- 文风(Simple Academic): 还可以,但仍然建议最后由人类再修一遍再正式提交。
这一点跟我自己的感觉很一致。任何被 AI “人类化”过的文本,就算已经不错了,还是值得再做几件事:
- 把句子再收紧一点
- 处理一下略显生硬的过渡
- 确保整体语气真的是你想要的
谁跟你说“完全不用后期人工编辑”,基本就是在卖梦。
再测它自带的 AI 写作功能
Clever AI Humanizer 还带了一个自己的 AI Writer,入口在这里:
https://aihumanizer.net/zhai-writer
<img alt=’ src=‘https://mepis.org/community/uploads/default/original/image-1766509028.png’ height=‘362’ width=‘534’>
{kind=link}
这个东西和一般的 humanizer 不太一样。它不是:
ChatGPT → 复制 → 粘进 humanizer → 祈祷
而是直接一步到位:写的同时就按“人类化”思路来写。这点挺关键,因为当“内容生成”和“人类化处理”本身就是同一套系统时,它可以从结构和用词上同时下手,尽量避开常见的“GPT 指纹”。
很多 AI humanizer 本质上只是把别的 AI 输出再改写一遍,这个是从零开始写。
AI Writer 的测试设置
这轮实验中,我这样设定:
- 风格:Casual(随意、口语化)
- 主题:AI humanization,并且在内容中提到 Clever AI Humanizer 本身
- 长度:要求 300 词
- 在提示词里故意加了一个错误信息,看它会怎么处理
<img alt=’ src=‘https://mepis.org/community/uploads/default/original/image-1766509031.png’ height=‘324’ width=‘516’>
{kind=link}
我不满意的一点:
它完全没给我 300 词。而是写了远远超出。
如果我说要 300 词,我想要的是围绕 300 左右,而不是 550 再加一声关怀问候。这是遇到的第一个比较明显的问题:对字数要求有点无视。
AI Writer 输出的 AI 检测结果
接着同样流程:上检测器。
- GPTZero:
显示为 0% AI,完全判定为人类。 - ZeroGPT:
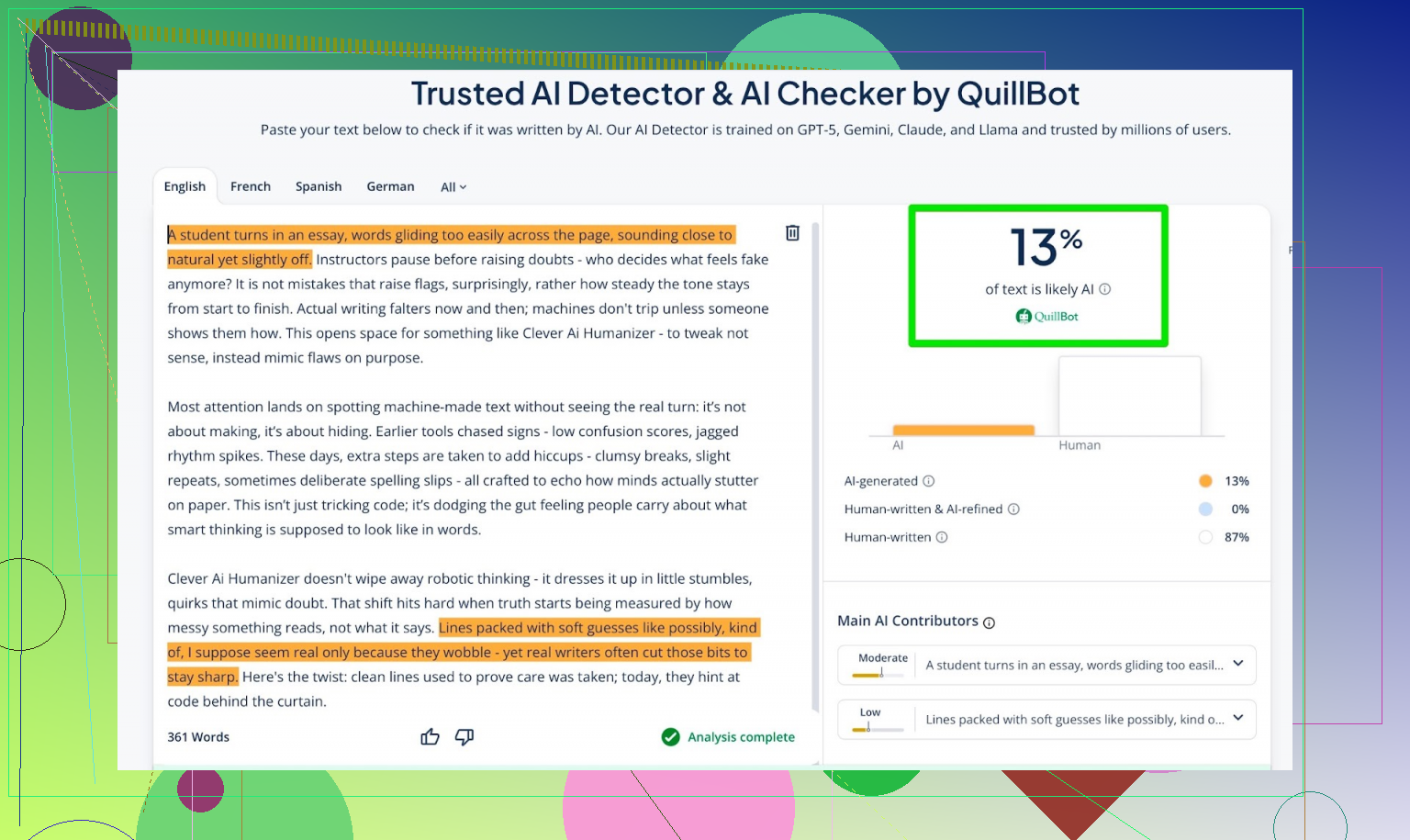
仍然是 0% AI,他们的指标下是 100% human。 - QuillBot AI Detector:
显示大约 13% AI 概率。
<img alt=’ src=‘https://mepis.org/community/uploads/default/original/image-1766509033.png’ height=‘350’ width=‘648’><img alt=’ src=‘https://mepis.org/community/uploads/default/original/image-1766509035.png’ height=‘424’ width=‘650’><img alt=’ src=‘https://mepis.org/community/uploads/default/original/image-1766509036.png’ height=‘338’ width=‘568’>
{kind=link}
{kind=link}
{kind=link}
考虑到 AI 检测器本来就非常不稳定,这一组成绩其实相当不错。
没有哪个工具会一眼认定“这显然是 AI 垃圾文”。QuillBot 把一小部分判成疑似 AI,但远远不到“机器写的,一看就假”的程度。
ChatGPT 5.2 对 AI Writer 输出的看法
我又把 AI Writer 生成的那段文字丢回给 ChatGPT 5.2 让它审稿。
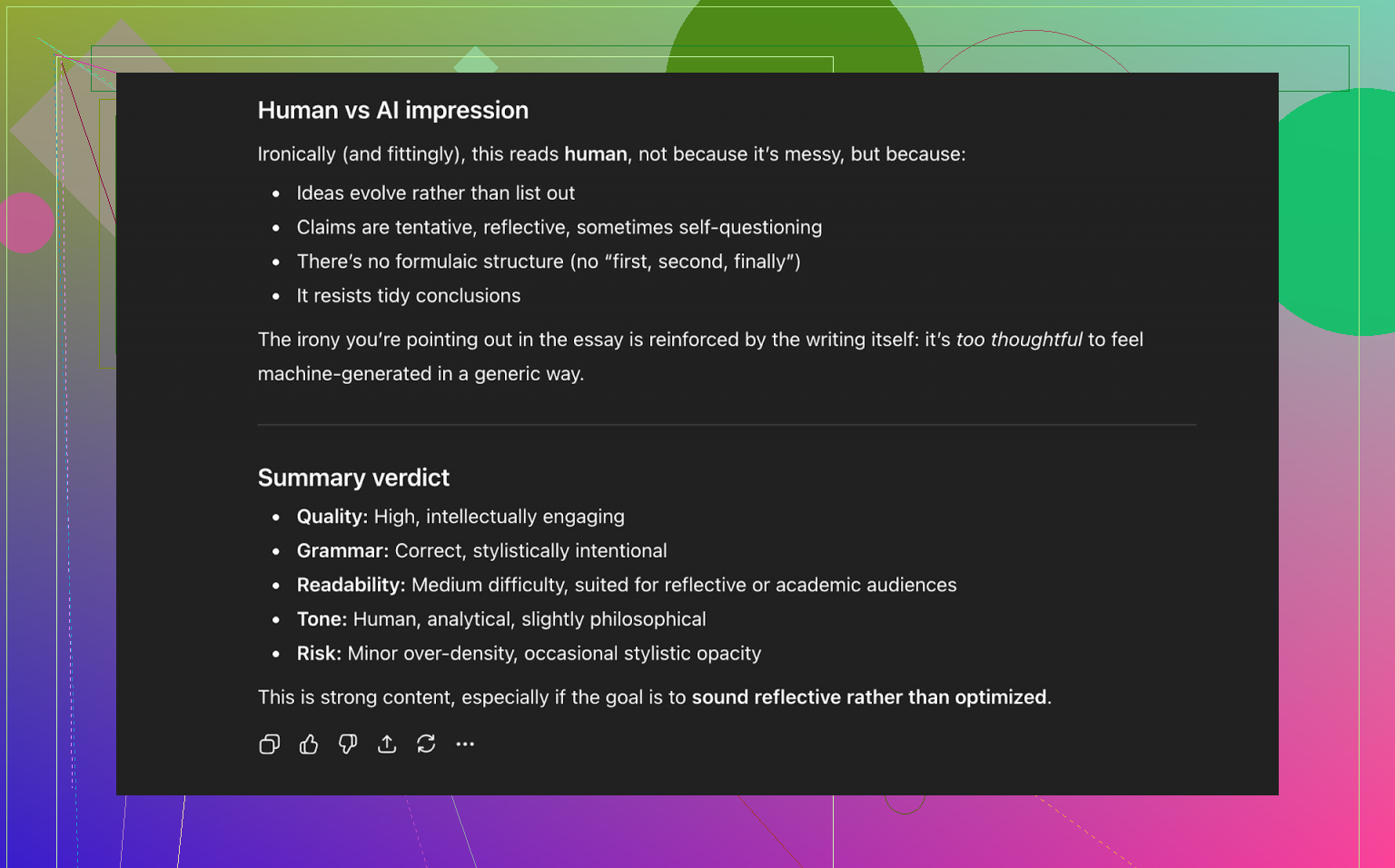
它的结论:
- 整体读起来非常接近人类写作
- 行文流畅
- 没有什么严重的语法翻车点
也就是说,Clever AI Humanizer 的结果不止是在三个主流检测器面前过关,在一个比较新的大模型眼里,从结构、语气和风格上看,也属于人类写作范畴。
和其他 humanizer 相比处于什么水平?
如果你正在挑工具,这可能是最有用的一段。
在我自己的测试里,Clever AI Humanizer 的表现明显优于:
- 这些免费选项:
Grammarly AI Humanizer、UnAIMyText、Ahrefs AI Humanizer、Humanizer AI Pro - 以及一些付费工具,比如:
Walter Writes AI、StealthGPT、Undetectable AI、WriteHuman AI、BypassGPT
下面是我当时做的汇总表,依据是 AI 检测器的评分(数字越低表示“越不像 AI”):
| 工具 | 是否免费 | AI 检测得分 |
|---|---|---|
| 是 | 6% | |
| Grammarly AI Humanizer | 是 | 88% |
| UnAIMyText | 是 | 84% |
| Ahrefs AI Humanizer | 是 | 90% |
| Humanizer AI Pro | 限免 | 79% |
| Walter Writes AI | 否 | 18% |
| StealthGPT | 否 | 14% |
| Undetectable AI | 否 | 11% |
| WriteHuman AI | 否 | 16% |
| BypassGPT | 限免 | 22% |
这些数字是我测试当时、在对应检测器上的结果。检测器和生成器都一直在进化,但在那个时间点的横向对比里,Clever AI Humanizer 基本压过了我试过的所有其他工具,尤其是在“免费档”里优势很明显。
Clever AI Humanizer 的不足之处
它不是魔法,也谈不上完美。你细看会发现几个明显短板:
-
字数控制很差
我说“300 词”,我希望落在那个区间,而不是直接给我一整篇长博客。它经常严重偏离要求。 -
仍然有一点“AI 味儿”
就算检测器判 0% AI,你有时候还是能隐约感觉到那种 AI 习惯性的句式节奏。看过足够多 AI 文的人,大脑会自动提醒你“有点像”。 -
不是严格的一比一改写
你把原文贴进去,它不会总是紧贴着原来的表达或结构来改,有时改动挺大。这可能正是它更能躲开检测的原因,但如果你需要高度忠实的重写,这点会让人不爽。 -
有些大模型有时仍会标出可疑片段
虽然几个主流公开检测器会说“像人写的”,但一些更先进的大模型在做风格分析时,偶尔还是会给出“整体很像人类,部分内容可能带有 AI 痕迹”的判断。
相对的优点是:
- 语法:稳定在 8–9 / 10 的水平。
- 可读性:不错。用来写博客、随笔、一般内容都足够自然。
而且它不会靠造假“人类错误”来迷惑检测器,比如刻意把“I”写成小写“i”,或者乱塞“teh”这种错别字。很多工具现在在走这条路,结果就是文本看起来像是在公交车上用手机打字没检查。
的确,乱搞拼写和标点可能会帮你多骗过几个检测器,但把成品文本的整体质量拉得更低。
再拉高一点视角:猫捉老鼠的游戏
即使你现在拿到的是:
- ZeroGPT:0% AI
- GPTZero:0% AI
- 其他检测器也都绿灯
你仍然没办法保证:
- 某家公司内部自研的检测系统
- 某个学校/机构自己训练的模型
- 未来版本更新后的工具
也会给出同样的结论。
所谓“AI 人类化”,本质就是一场持续进行的军备竞赛:
- AI 以某种模式写作
- AI 检测器学会识别这种模式
- AI humanizer 打乱这个模式
- 检测器再针对这些“躲避技巧”重新训练
- 如此循环
以当前节点来看,Clever AI Humanizer 在这场游戏里,算是表现很好的一个,尤其考虑到它还是个免费的服务。
但没有任何一个工具能永远“完全不可检测”。整个生态不是这么运行的。
那么,Clever AI Humanizer 值得用吗?
如果你的问题是:
“现在我能用到的、最靠谱的免费 AI humanizer 是哪个?”
以我这轮测试结果来看:是它。
- 它比我试过的所有免费工具表现更好。
- 效果甚至不输、甚至超过了不少付费工具。
- 自带一个 AI Writer,可以一边生成、一边按“人类化”思路来写。
- 不会为了糊弄检测器,故意把语法写烂或夹杂大量假错别字。
但期望值要放在合理区间:
- 一定要最后自己再编辑一遍。
- 别把它当成什么学术作业的“免死金牌”。
- 要接受偶尔有 AI 风格痕迹、以及字数常常超标这两件事。
再强调一次,如果你要用它,先确认你打开的是:
https://aihumanizer.net/zh
而不是某个乱七八糟的仿冒域名。
想继续深挖的话,这里有一些额外链接
网上有不少关于 AI humanizer 的讨论和横评,可以参考:
-
多个 AI 人类化工具的对比和检测截图整理:
https://www.reddit.com/r/DataRecoveryHelp/comments/1oqwdib/best_ai_humanizer/?tl=zh -
针对 Clever AI Humanizer 的 Reddit 详细评测帖:
https://www.reddit.com/r/DataRecoveryHelp/comments/1ptugsf/clever_ai_humanizer_review/?tl=zh
<img alt=’ src=‘https://mepis.org/community/uploads/default/original/image-1766509038.png’ height=‘387’ width=‘578’><img alt=’ src=‘https://mepis.org/community/uploads/default/original/image-1766509040.png’ height=‘358’ width=‘576’>
{kind=link}
{kind=link}
简短结论:你的工具确实可以听起来自然,但目前给人的感觉更像是“非常聪明的改写器”,而不是“有清晰人声的作者”,至少从我看到的类似行为来看是这样。
既然 @mikeappsreviewer 已经把它拿去和各种检测器硬刚过了,我就不再讨论“AI 和检测器谁赢谁输”,而是转向一个问题:真实读者会怎么感受它。
我会从这些方面入手改进:
1. “AI 节奏感”问题
即使文本能通过检测,仍然会带着一股淡淡的“AI 节奏”:
- 句子长度都差不多
- 过渡太顺、太通用
- 段落结构常常非常规整:先提论点 → 稍微展开 → 安全收个尾
但真实的人要凌乱得多。他们会:
- 偶尔把重点丢到最前面
- 突然来一句很短、很有力的话
- 在生气或兴奋时,直接打破“完美结构”
实用改进建议:
加一个后处理步骤,刻意去:
- 更大幅度地拉开句子长短差异
- 混合使用“很紧凑”和“略微啰嗦”的句子
- 在风格 = 休闲 / 对话时,允许偶尔出现残句
再给用户一个“结构松散度”的滑杆。现在大多数工具都太“整洁保守”。
2. 过度改写 vs 忠实原意
这一点上我不完全同意 @mikeappsreviewer 的看法:大幅重写并不总是好事。
有时候你的工具会为了“足够不同”而偏离原始想法太多。这样虽然有利于避开检测,但对于以下场景非常糟糕:
- 法务 / 合规文本
- 技术文档
- 客户文案,对措辞极度敏感的那种
实用改进建议:增加“改写力度”档位
例如:
- 低: 保留结构和关键措辞,只打散最“GPT 味”的部分
- 中: 现在的默认水平
- 高: 允许大幅重写、重排,甚至适度加入解释
目前整体感觉偏在中 / 高之间,对那些必须精准的场景来说会让人很慌。
3. 语气不像在真实语境里的真人
这是检测器完全帮不上忙、但读者一眼能感受到的地方。
真实的人在写:
- “简化学术风”时,有时会犹豫、自相矛盾,或者说“我不太确定,但……”
- “休闲”语气时,会带一点插科打诨、小观点、微小情绪波动
你这个工具(和市面上类似工具)产出的内容往往会:
- 除非要求,否则尽量避免用第一人称
- 保持中立、安全
- 缺乏具体的、带体感的细节
实用改进建议:
增加一些可选开关,例如:
- “允许轻微观点 / 立场”
- “加入少量类似个人语气的插话(不编造人生经历,只调语气)”
- “在休闲模式下,自然地使用‘我’ / ‘我们’”
还有一点非常关键:不要伪造具体人生经历。这会瞬间摧毁信任。
4. 字数控制不是可有可无的小功能
在这一点上我完全赞同 @mikeappsreviewer:字数控制目前有问题,而且比想象中重要得多。
在学术 / 客户工作场景里,这非常关键:
- 300 字不能莫名其妙膨胀成 550
- 学生 / 打工人要对标任务要求,而不是跟老师 / 主管解释“工具自己写多了”
实用改进建议:
- 硬上限模式:“绝不超过 X 字的 5% 以上”
- 软目标模式:“尽量接近 X,但内容质量优先于精确字数”
如果两种都能提供,你的工具会比绝大多数只会“疯狂加段落”的“人性化工具”实用得多。
5. 让用户真正能定制“自己的声音”
现在大多数 humanizer 都是那 4 个老配方:休闲、学术、正式、营销。但人的写作风格远远不止这几类。
如果你真想让输出像人写的,就应该让用户可以:
- 调节“直截了当 vs 委婉含蓄”的尺度
- 调节“信息密度 vs 手把手解释”的尺度(短而密 vs 细致讲解)
- 选择“直接切题 / 不要开场白” vs “有一个温和的铺垫”
真实写作者都有这些习惯。对齐这些,比任何“反检测技巧”都更有用。
6. 用真实读者盲测,而不只是看工具分数
与其只跑检测器和让大模型自己点评,不如:
- 从你的工具里取几段输出
- 和真人写的文本、明显的原始 AI 文本混在一起
- 请 10–20 个普通读者给每段打标签:
- 肯定是人写的
- 大概是人写的
- 不确定
- 大概是 AI
- 肯定是 AI
如果你家 Clever AI Humanizer 的输出,大部分落在“大概是人写的 / 不确定”,那就算不错。
如果很多人一眼就说“这是 AI 写的”,那么检测器蒙混过去也没有太大意义。
7. Clever AI Humanizer 目前真正的优势
在这些批评之外,你这工具其实在一些方面已经不错了:
- 已经明显强过大部分免费人性化工具,不是只会乱换同义词或故意打错字那种
- 语法基本保持干净,而不是刻意写坏
- 内置“从零开始直接写得更像人”的 AI 写作功能,这个思路本身挺聪明
如果有人现在就想找一个免费的 AI humanizer,Clever AI Humanizer 确实是我会愿意直接点名的少数之一,前提是他们明白自己还得再编辑一轮。
8. 如果我是你,接下来会做的事情
如果目标是让真实读者觉得自然可信,而不仅仅是“通过检测器”:
- 增加可控维度:
- 改写力度
- 语气松散度
- 句子长短变化幅度
- 修好字数控制逻辑,真正尊重任务约束。
- 做真正的盲测用户调研并公布结果,而不是只晒检测器截图。
- 增加一个“轻度人性化”模式,在保留原结构的前提下,只适度打破模式化。
检测器永远在变。要是 Clever AI Humanizer 能成为那个既重视“读者感受”,又兼顾检测分数,而不是只追“0% AI 截图”的工具,它就会脱颖而出,而不是变成另一款纯粹的“绕检测机器”。
现在你已经挺接近了,但整体优化重点还是偏“系统”多于“人”。
短评版:你的工具已经足够让“真实读者”使用,但整体更像是“学会礼貌的精致 AI”,而不是一个有自己观点的人。能骗过检测器这件事,本身是最无聊的部分。
@mikeappsreviewer 和 @caminantenocturno 已经聊过检测器、行文流畅度、节奏等问题,所以我换个角度:当你是为了“看懂内容”而不是“看分数”去读时,它给人的真实感觉。
1. 解释得清楚,却很少真正“在乎”什么
我看到的 Clever AI Humanizer 输出通常都是:
- 表达清晰
- 结构合理
- 语法扎实
但几乎从不让人感觉“这个人自己也有点赌注在里面”。读起来像一个非常懂人情世故、但从不强烈表态的实习生。
真实的人类会:
- 做一些细微的价值判断
- 表现出一点点偏向
- 偶尔听得出无聊、惊讶或不爽
而你的工具基本把这些都抹平了。是的,它看起来不像机器人,但常常像一封非常谨慎、HR 审核过的邮件。
具体建议:
加一个“立场 / 辣度”滑杆:
- 0:完全中立,教科书腔
- 1:轻微偏好,柔和观点
- 2:明显倾向一边,但不变成发疯吐槽
现在的感觉像是被锁死在 0.5。
2. 所有内容的“重要程度”几乎一样
这是检测器不会告诉你的:人类会用“强调”。他们会:
- 把关键句子写得更短
- 在重要观点前后故意打破一点原有节奏
- 偶尔重复一个词或短语来加重语气
你现在的模式把所有内容都调成了同一个温度,没有起伏。
实用调整:
在“随意”“博客风”这类模式里,允许:
- 短促的“点题句”,比如“真正的问题在这里。”
- 偶尔的重复,比如“看起来很干净。干净得有点不自然。”
- 长短句之间的对比更明显
不是随机变化,而是为了“强调”而刻意的变化。
3. 它几乎“太连贯”了
这一点上我和 @mikeappsreviewer 以及 @caminantenocturno 有点分歧。
他们更关注节奏和结构。我反而觉得更大的“AI 痕迹”是过度连贯:
- 过渡永远顺理成章
- 段落几乎从不稍微游离
- 从来没有半截想法就戛然而止
人类写长文的时候,会有点神游,然后再拉回来。
与其只是一味打磨,不如引入一点“可控的自然走神”:
- 一句稍微偏题的插话,然后再回到主线
- 偶尔有点突兀的转场
- 有的段落以一个“嗯,就这样吧”式的结尾收尾,而不是标准的总结句
用得好的话,会更像“写出来的东西”,而不是“工程化产物”。
4. 你高估了大家对“0% AI 检测率”的在意程度
直说:很多真实场景里,读者不在乎它是不是 AI 写的,他们在乎的是:
- 清不清楚
- 有没有切题
- 像不像套话
- 有没有针对自己的情境去写
现在的 Clever AI Humanizer 在“非机器人感的通用文本”这方面做得不错,这比直接复制 GPT 好一截,但还不是终点形态。
我反而会优先考虑:
- 加一点点场景化理解
- 映射用户约束(读者是谁?老板?老师?博客读者?)
- 提供诸如“经理周报”“大学讨论区回复”“落地页开头文案”等预设
这些预设对“读者的主观感受”的影响,远大于在 GPTZero 上刷出一个 0%。
5. 你已经明显领先很多“人类化”工具的地方
有几点你确实比一大票竞品做得好:
- 不刻意乱写语法或加假错别字
- 不只是机械地替换同义词
- 从一开始就做“近似人类风格写作”的集成写作,比“先 GPT 一段 → 再随机改写”这类流程聪明得多
从真实用户视角看,如果有人在横向比较工具:
Clever AI Humanizer 至少是那种我会说“可以试试看”的类型,只要他们知道最后还要自己花几分钟过一遍。
6. 一些会让它明显更“像真人”的具体改进
如果要加可调选项,我会优先这些,而不是再去卷检测器:
-
受众选择器
- 老师 / 教授
- 老板 / 利益相关方
- 普通博客读者
- 技术同行
一个选项就要明显影响:语气、术语密度、解释程度。
-
风险容忍度滑杆
- 稳妥中立
- 稍微有点观点
- 直接坦率
让用户决定它是“企业公关腔”还是“正常人说话”。
-
内容压缩控制
- “尽量短、信息密” vs “多解释一点”
很多工具会过度解释,而真实的人在有字数限制时往往不会。
- “尽量短、信息密” vs “多解释一点”
-
微小“人类习惯用语”(不编故事)
不是编造经历,而是自然的小动作:- “说实话”“公道点讲”“麻烦的地方在于……”
- 在随意模式下,偶尔来一个反问句
但要做得足够克制和多样化,不要变成另一种模板痕迹。
7. 以“真实用户”的身份,我现在会怎么用它
如果诚实一点说,这才是 Clever AI Humanizer 目前最有价值的工作流:
- 先用任意 AI(或内置写手)打草稿
- 丢进 Clever AI Humanizer 做去模式化处理
- 自己花 5–10 分钟加上:
- 一两句明显的个人观点
- 一个本地化的小例子或细节
- 两三处刻意的“强调点”(短句、带点情绪的句子)
到这个程度,对绝大多数读者来说,就已经“足够像人”,他们会停止纠结“怎么写出来的”,而开始专心“看写了什么”。
所以,总体来说:它已经不只是“骗基础检测器”的玩具,但也还没到“这肯定是某个具体的人、带着具体情绪写的”的程度。你们其实已经比大部分工具近多了,如果把重心从“展示检测截图”转移到“研究读者心理”,Clever AI Humanizer 完全有机会从“又一个绕过检测的小工具”升级成那个大家默认会先去试的选择。
撇开其他人已经谈到的节奏感和检测器不说,这里换个角度:你的“聪明 AI Humanizer”作为一个真正有人愿意长期采用的产品,看起来如何。
你的工具已经做对的地方
-
检测器表现已经“够用”
你不需要永远在每个检测器上都做到 0%。正如 @caminantenocturno 和 @mikeappsreviewer 展示的,你现在的分数已经把你放在“可用”而不是“噱头”这一档。这已经比大多数“人性化工具”强很多。 -
可读,而不是被肢解
和一大堆像伪原创垃圾一样的绕过工具不同,Clever AI Humanizer 能保持语法完整。对于客户和编辑来说,这比检测器猜出 6% 还是 16% AI 重要得多。 -
集成写作功能是真正实用的
我喜欢你能一口气完成生成和人性化处理,而不是像在另一个模型上再套一层同义词过滤器。这在结构上就是优势,即使字数现在有点失控。
它仍然像“打了领带的 AI”的地方
这里我和 @himmelsjager 有点不同意见:氛围不只是“中性”,而是怪异地一致——太一致了。
大规模的人类文本,在特定的地方会很乱:
- 有时候会非常狠地压缩一个观点
- 有时候会絮叨整整一段
- 有时候会突然给出一个特别生动的细节,然后又回到抽象的说法
你的工具确实在表面形式上做了变化,但不够“有意图”的变化。它保留了那种安全、光线均匀的感觉——对有经验的读者来说,这种感觉就写着“模型产物”,即使检测器不吭声。
如果你想让它像真人,就需要受控的不对称,而不只是“长短句混搭”。
具体的产品调整,没有空话
-
模式模板要和使用场景绑定,而不是和氛围形容词绑定
不要只停留在“简单学术”“轻松随意”这类标签,增加带有约束和利害关系含义的预设:
- “有评分的作业回答”
- “经理项目进度更新”
- “面向客户的博客开头”
- “技术同事之间的解释说明”
每种模式都应该改变:
- 犹豫语 vs 确信语 的比例
- 会不会反复重讲背景
- 结论收得多紧凑
这样一来,输出会立刻变成“写给某个人”的,而不只是“出自某个东西”的。
-
对压缩程度的真实控制
现在的行为:用户要 300 词,结果得到“惊喜长文”。
不要只是尝试凑个数字,给用户一条明确的滑杆:- “简短密集”
- “平衡”
- “详细解释”
然后真正执行一个硬范围:
除非用户明确选了“详细解释”,否则不要超过目标字数 2 倍。
这更像人类行为:当别人说“你只有 300 字”,人是会把它当真限制的。 -
观点与风险的刻度调节
你现在的内容非常 HR 安全。能用,但无聊。
给用户一个三档控制:
- 中立:描述、比较、尽量不选边
- 轻微立场:小幅价值判断,用诸如“在实际中往往意味着”这样的表述
- 明确立场:清楚地写出“这有效,那无效”,但不演变成发牢骚
让用户自己决定要多少“锋芒”。这样才能把一般的清晰度变成听起来像是一个真正在下判断的人。
-
注入真正的小层面具体细节,而不是假“个性”
避免假故事,但允许真实感强的小锚点:
- 一个具体情境:“比如,把季度更新重写一遍,好让你的总监不会一扫而过”
- 一点时间感:“在现在这一批工具里”“在当前这个阶段”
这些生成成本很低、风险小,却能让文本看起来是扎在现实世界里,而不是飘在真空中。
就目前版本而言,Clever AI Humanizer 的优点
- 在公开检测工具上的表现很强
- 默认就有干净的语法和结构
- 不玩“随机打错字”这一套
- 集成 AI 写作功能简化了工作流程
- 免费使用,便于试用和迁移
阻碍它真正“像人”的缺点
- 对字数和类似“写作简报”的约束执行得很弱
- 语气长期停留在谨慎、中性、中间层
- 输出给人的感觉是“处处都差不多对”,而不是在某些地方特别锐利、某些地方允许粗糙
- 各模式里还没有足够多的“面向特定受众”的行为预设
我现在会如何现实地使用它
如果我是重度用户,现在会这样用:
- 用 Clever AI Humanizer 的写作功能或别的模型先打草稿。
- 再用你的工具跑一遍,选择一个匹配场景的模式(简单学术、轻松随意等)。
- 自己花 5 分钟手工:
- 插入一两条清晰的个人观点
- 删掉每一段末尾那些看起来像“总结句”的废话
- 加一个来自自己真实背景的具体例子
做完这些之后,几乎没有普通读者会在意有没有 AI 参与。他们只会在意内容是不是清楚、不别扭,而且是写给他们看的。
所以你已经超出“只是骗过基础检测器”的阶段了。下一版应该少点“再多赢一个检测器”的焦虑,多思考怎样帮用户变成“在某种具体情境下的某一种人”。这个空档现在大多数工具——包括 @caminantenocturno 和 @mikeappsreviewer 对比过的那些——依然敞着。